11.2. Performance test
One of the more important test of our project is to evaluate the performance of the two platforms. As dotnetprocessing uses the .NET Framework, that is embedded in the operating system and we don't need to run the Java Virtual Machine, it should be more efficient and faster. Next, we will show that we were right. To make these tests, we show in the sketch the average framerate and the average miliseconds that take long a loop. For these calculations, we use millis() primitive and framerate environment variable.
In the code of one of the examples, you can see how we do this calculations:
Example 11-1. Modified code to show performance
// Sine_Cosine
// by REAS
// Linear movement with sin() and cos().
// Numbers between 0 and PI*2 (TWO_PI which is roughly 6.28)
// are put into these functions and numbers between -1 and 1 are
// returned. These values are then scaled to produce larger movements.
// Updated 21 August 2002
int i = 45;
int j = 225;
float pos1 = 0;
float pos2 = 0;
float pos3 = 0;
float pos4 = 0;
int sc = 40;
int radio_bola = 100;
// PERFORMANCE -------------------------------------
double mediams = 0;
double mediafr = 0;
int ii = 0;
void setup()
{
size(500, 500);
noStroke();
smooth();
// PERFORMANCE -------------------------------------
// framerate(60);
PFont font;
font = createFont("Tahoma",8);
textFont(font, 12);
}
void draw()
{
background(0);
fill(51);
rect(150, 150, 200, 200);
fill(153);
ellipse(pos1, 75, radio_bola , radio_bola );
fill(255);
ellipse(75, pos2, radio_bola , radio_bola );
fill(153);
ellipse(pos3, 425, radio_bola , radio_bola );
fill(255);
ellipse(425, pos4, radio_bola , radio_bola );
i += 10;
j -= 10;
if(i > 405) {
i = 45;
j = 225;
}
float ang1 = radians(i); // convert degrees to radians
float ang2 = radians(j); // convert degrees to radians
pos1 = width/2 + (2 * sc * cos(ang1));
pos2 = width/2 + (2 * sc * sin(ang1));
pos3 = width/2 + (2 * sc * cos(ang2));
pos4 = width/2 + (2 * sc * sin(ang2));
// PERFORMANCE -------------------------------------
mediams = ((mediams * ii) + duration.TotalMilliseconds) / (ii +1);
mediafr = ((mediafr * ii) + framerate) / (ii +1);
ii++;
text("ms por iteracion: "+mediams.ToString(), 10, 10);
text("framerate: "+mediafr.ToString(), 10, 30);
}
|
We deactivate the frameset so that sketches can be runned as fast as it could be possible. So we can get the values when every platform is forced to be runned in it highest performance. The execution of every test was about one minute. With this time, the values of the variables had enought time to be stable.
Next, we show our first test: we executed the Bounce example with dotnetprocessing and with processing and we get these values:
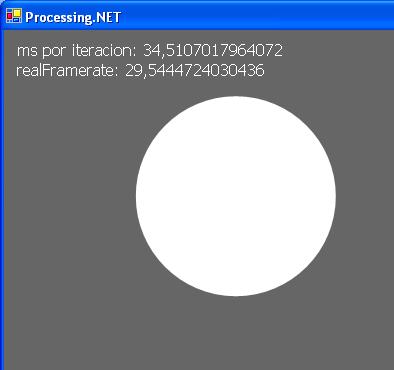
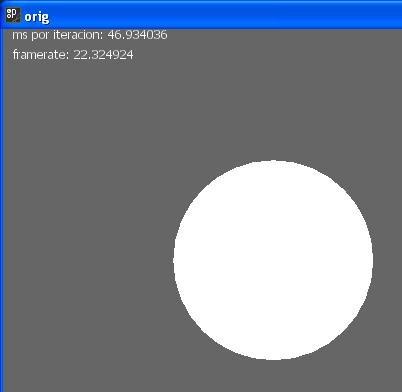
As we can see, dotnetprocessing is 12 milliseconds faster per loop, and so, it can display about 7 frames per second more.
Next example is Collision, executed in both platforms. This is an interactive sketch where we can play with the ball, as it was a ping pong game. We played with every sketch one minut and only lost one ball in every one.
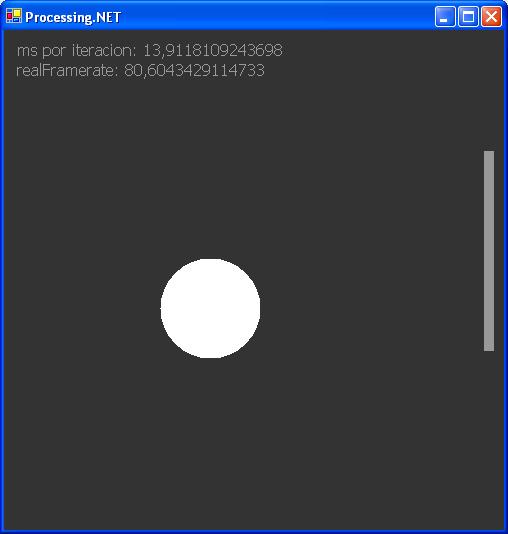
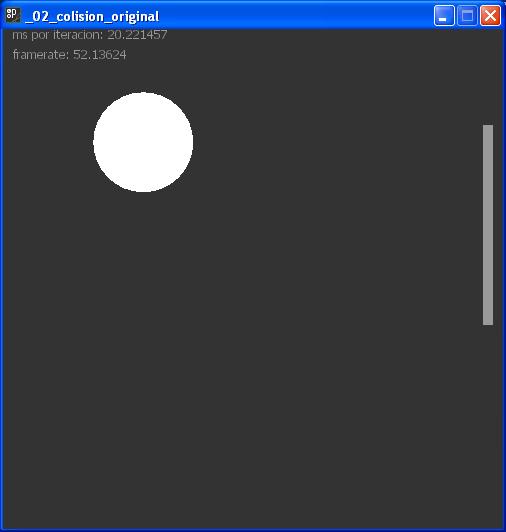
In this test, we can see that our processing framerate was much more high that in the original language.
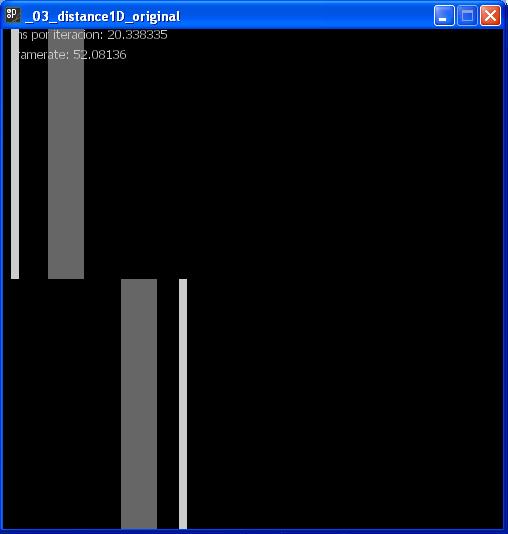
We made more tests to be sure that it was always more efficient, and it wasn't chance. The next example is Distance1D. The sketch is divided in 2 parts: the top and the bottom. The bars from the top are moving to the opposite side of the bottom ones. It also is interactive, and the movement of the mouse makes the bars be faster, and set de direction of the bars movements:

The last test was made with SineCosine example. Here we have a fixed square and 4 balls around it. The balls are moved from side to side of the square. It was not a interactive sketch, but has 4 objects in movement at the time:

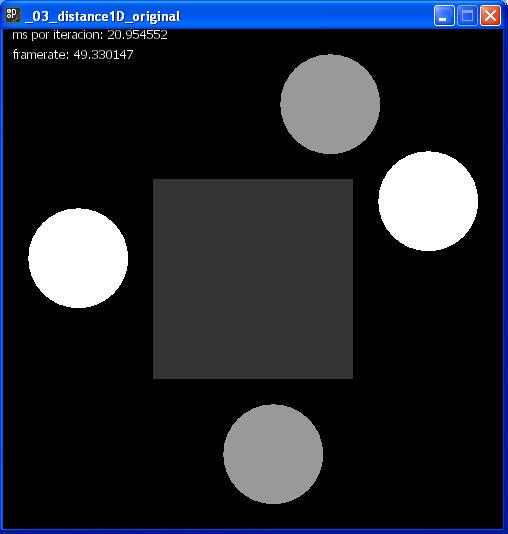
As we had proved, in all tests dotnetprocessing had a lower time of looping and a bigger framerate. Then, we can affirm that the executions with .NET Framework are more efficients than with Java Virtual Machine in all cases: interactives or not sketches.